Database Transaction and Isolation
Overview
Transaction과 Isolation 기초 개념 정리
Background
작년에 Backend 업무 처음 시작할 때, payment/subscription 관련 로직을 이해하기 위해 개인 노션에 정리두었던 내용이다. 첫번째 article로 우선 단순히 옮겨둔다
Transaction
A database transaction is a unit of work performed within a database management system against a database, treated independently from other transactions. Transactions have two main purposes:
- To enable reliable recovery from failures and maintain database consistency, even when execution stops unexpectedly.
- To provide isolation between concurrent database programs, preventing erroneous outcomes.
A transaction is a single unit of work, sometimes involving multiple operations. For example, a bank transfer subtracts an amount from one account and adds it to another.
Transactions must be atomic (complete or no effect), consistent (conform to constraints), isolated (not affect others), and durable (written to persistent storage).[1] These properties are known by the acronym ACID.
A transactional database is a DBMS that provides the ACID properties for a bracketed set of database operations (begin-commit). Transactions ensure that the database is always in a consistent state, even in the event of concurrent updates and failures.[2] All the write operations within a transaction have an all-or-nothing effect, that is, either the transaction succeeds and all writes take effect, or otherwise, the database is brought to a state that does not include any of the writes of the transaction.
Transactions also ensure that the effect of concurrent transactions satisfies certain guarantees, known as isolation level. The highest isolation level is serializability, which guarantees that the effect of concurrent transactions is equivalent to their serial (i.e. sequential) execution.
Isolation
It determines how transaction integrity is visible to other users and systems.
A lower isolation level increases the ability of many users to access the same data at the same time, but also increases the number of concurrency effects (such as dirty reads or lost updates) users might encounter. Conversely, a higher isolation level reduces the types of concurrency effects that users may encounter, but requires more system resources and increases the chances that one transaction will block another.
Read Phenomena
The ANSI/ISO standard SQL 92 refers to three different read phenomena when a transaction retrieves data that another transaction might have updated.
Dirty Read (aka uncommitted dependency)
Occurs when a transaction retrieves a row that has been updated by another transaction that is not yet committed.
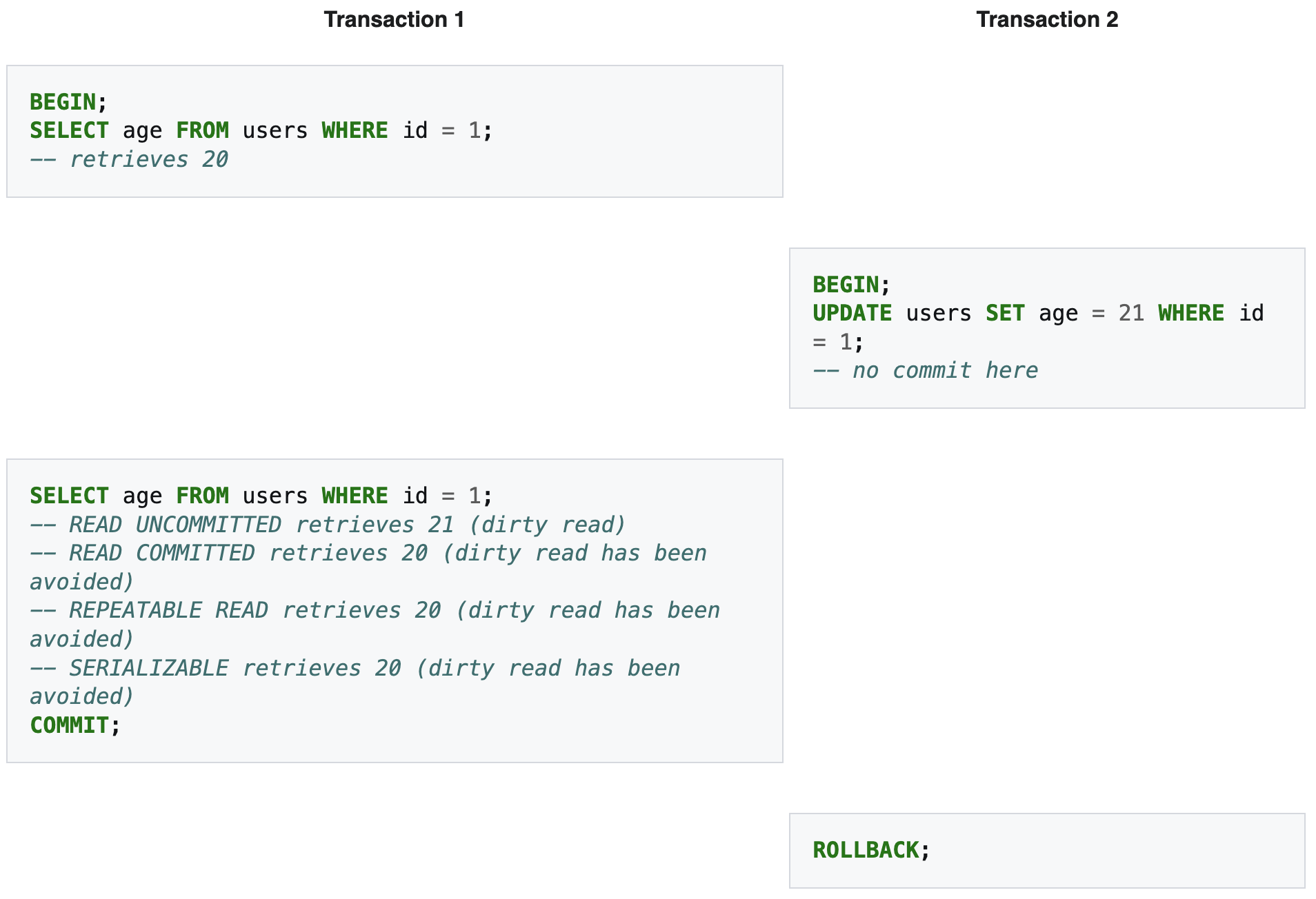
Non-repeatable Reads
Occurs when a transaction retrieves a row twice and that row is updated by another transaction that is committed in between.

Phantom Reads
Occurs when a transaction retrieves a set of rows twice and new rows are inserted into or removed from that set by another transaction that is committed in between.
Isolation Levels
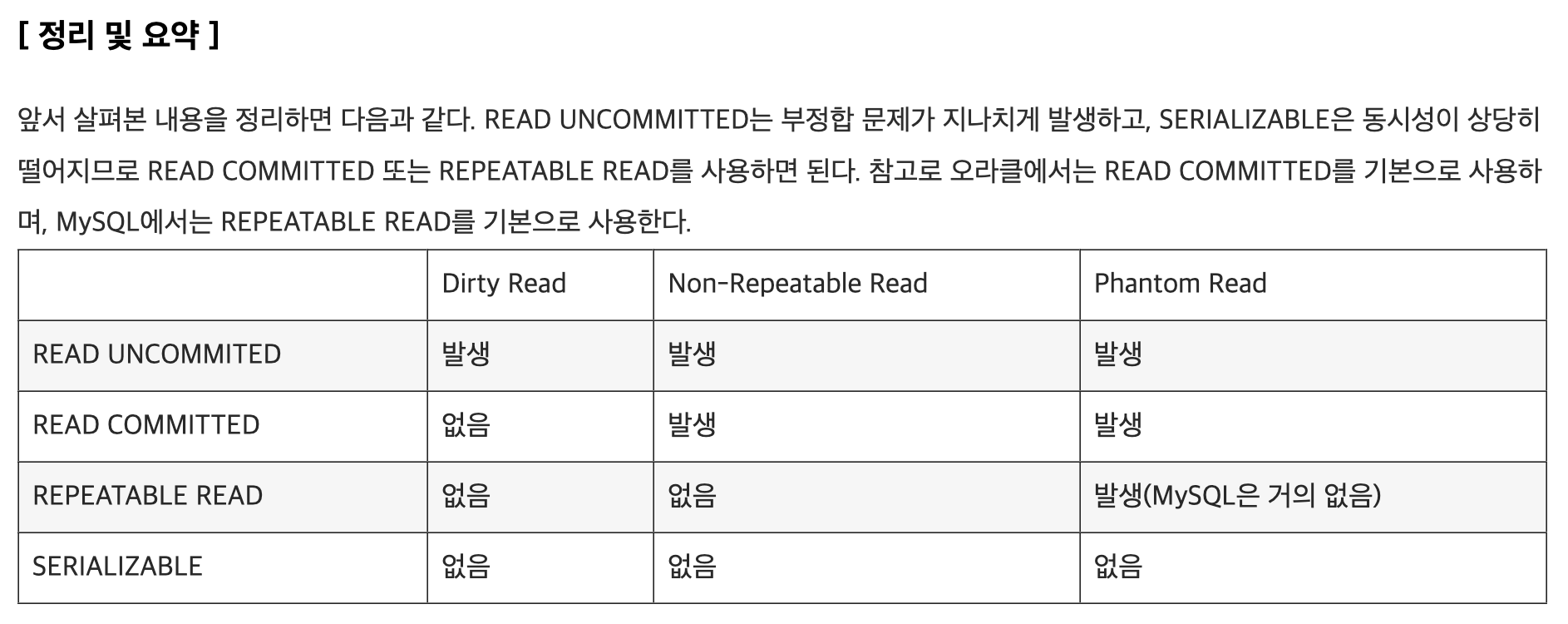
Serializable
- 한 트랜잭션에서 사용하는 데이터를 다른 트랜잭션에서 접근 불가
- 트랜잭션이 커밋될때까지 모든 데이터에 잠금이 설정되어 다른 트랜잭션에서 해당 데이터를 변경할 수 없다.
- 완벽한 읽기 일관성 모드를 제공함
not really used due to lacking performance speed.
Repeatable Reads
트랜잭션이 범위 내에서 조회한 데이터 내용이 항상 동일함을 보장함
다른 사용자는 트랜잭션 영역에 해당되는 데이터에 대한 수정 불가능
- 트랜잭션이 시작되기 전에 COMMIT된 내용에 대해서만 조회할 수 있는 격리수준이다.
- MySQL에서는 트랜잭션마다 트랜잭션 ID를 부여하여 트랜잭션 ID보다 작은 트랜잭션 번호에서 변경하는 것만 읽게 된다.
- 변경되기 전 레코드는 Undo 공간에 백업해두고 실제 레코드 값을 변경한다.
- Read Commited와 다른 점은 한 트랜잭션이 조회한 데이터는 트랜잭션이 종료될 때까지 다른 트랜잭션이 변경하거나 삭제하는 것을 막으므로, 한번 조회한 데이터는 반복적으로 조회해도 같은 값을 반환한다.
Read Committed
can view commited transaction data.
실제 테이블 값을 가져오는 것이 아니라 Undo 영역(Undo 영역은 데이터의 변경이 있을 경우 이전의 데이터를 보관하는 곳)의 백업된 레코드에서 값을 가져온다.
Read Uncommitted
can read uncommited data or data in process. not really used due to heavy data inconsistency.
In MySQL…
A lock is the database’s promise to temporarily reserve some resource so concurrent transactions don’t step on each other. While a lock is held, other transactions that would conflict must wait (or error with NOWAIT/SKIP LOCKED).
InnoDB uses row/index-level locks most of the time (not whole tables), plus a few special kinds to prevent edge-case anomalies. The official docs divide them like this: shared/exclusive, intention, record, gap, next-key, insert-intention, and special AUTO-INC; and MySQL also has metadata locks (MDL) for DDL safety.
💡 Quick summary table
| Acronym | Full Name | Category | What it affects | Example |
|---|---|---|---|---|
| DDL | Data Definition Language | Schema-level | Table structure | CREATE TABLE, ALTER TABLE |
| DML | Data Manipulation Language | Data-level | Row data | INSERT, UPDATE, DELETE, SELECT |
| FK | Foreign Key | Constraint | Parent-child row relationships | FOREIGN KEY (...) REFERENCES ... |
| MDL | Metadata Lock | Lock type | Prevents schema change/read conflicts | Blocks ALTER TABLE while queries run |
| dup-key | Duplicate Key | Constraint violation | Unique key conflict | “Duplicate entry” error |
Basic lock modes
- Shared (S) lock: “I’m reading this row.” Multiple readers can share it; writers must wait. dev.mysql.com
- Exclusive (X) lock: “I will write this row.” Only one writer; blocks readers that want a shared lock and other writers.
Row/index-level flavors
InnoDB’s “row” locks are actually index record locks. Important flavors:
- Record lock: locks the index entry for matched rows.
- Gap lock: locks only the gap between index entries (prevents inserts into that range).
- Next-key lock: record lock + the gap before it (prevents both updating the row and inserting a new row right before it). This is how REPEATABLE READ prevents phantoms.
How it ties to isolation levels (quick map)
- READ UNCOMMITTED: snapshot rules are weakest; not generally used with InnoDB.
- READ COMMITTED: locking reads/UPDATE/DELETE record-lock only; no gap locks (except FK/dup-key). Fewer blockers; possible phantoms.
- REPEATABLE READ (MySQL default): uses next-key locks on searches/scans → prevents phantoms; stronger blocking.
- SERIALIZABLE: MySQL upgrades plain SELECTs to locking behavior that further reduces concurrency.
Refs
- https://dev.mysql.com/doc/refman/8.4/en/innodb-transaction-isolation-levels.html
- https://chatgpt.com/share/68f0b74c-c43c-8002-90e9-a3461bc56c5a
- https://mangkyu.tistory.com/299#google_vignette
- https://velog.io/@eunsiver/%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98-%EA%B2%A9%EB%A6%AC-%EC%88%98%EC%A4%80Transaction-Isolation-Level-q2ohkr3n